Incident Response Runbook
This guide is meant to outline the process for running a common incident response. It ensures that we are working on the right problem, keeping all stakeholders informed, assigning focus roles, and discovering the root cause or at least mitigating the issue.
Incident Priorities
P0 (Critical Incident)
A P0 incident is a complete outage or a severe degradation that affects all customers and requires immediate attention.
P1 (Major Incident)
A P1 incident refers to a customer-visible outage that interrupts the functionality or behavior of the platform.
P2 (Minor Incident)
A P2 incident may affect some functionality but doesn’t lead to an entire system failure.
P3 (Low Impact Incident)
A P3 incident may have an impact, but it’s something that can be dealt with in a routine manner.
Examples of P1 Incidents:
- The Customer is unable to deploy
- The account ran out of nodes to launch
- Certificate expires
- Config Management system is down
- Database is down
Base Process
Five Whys Technique
The primary goal of the Five whys technique is to determine the root cause of a defect or problem by repeatedly asking “Why?”
Why? – The service is down. (First why)
Why? – The database connection failed. (Second why)
Why? – The authentication token has expired. (Third why)
Why? – The token was not refreshed. (Fourth why)
Why? – The scheduled job for token refreshment failed. (Fifth why, a root cause)
Note: Please read about why the Five Why’s is a good start and more.
Incident Response Steps
- Validate the problem and ensure it is a P1 Incident.
- Create a Jira Ticket in the IM board.
- Create a Slack war room, slack public channel, and invite all necessary personnel.
- Announce in #tech-outage.
- Assign Roles.
- Isolate and record experiments by coordinating with the roles of the IM.
- Log for future Post Mortem.
- Update Stakeholders every 15 to 45 minutes.
- Log all manual changes.
- Five Whys.
- Verify recovery.
- Announce resolved (Yellow Status).
- Announce resolved (Green status) when tech-debt is cleaned up after the customer verifies the fix.
- Start Incident Report.
- Schedule a Post Mortem.
Roles
- Communicator: Provides updates, including those of no progress, to the stakeholders.
- Recorder: Logs what is tried and did not work, creating an incident document following the base Jira procedure.
- Lead: Works with the communicator and team to coordinate different ICs to determine the root cause.
- IC (Incident Commander): Coordinates with the lead and other ICs to ensure that experiments do not interfere with other efforts.
Follow the incident response process by focusing on what we are fixing, what is broken, and how data did or did not verify our assumptions. We follow an experimental process illustrated below, while communicating the step of the experiment with the team.
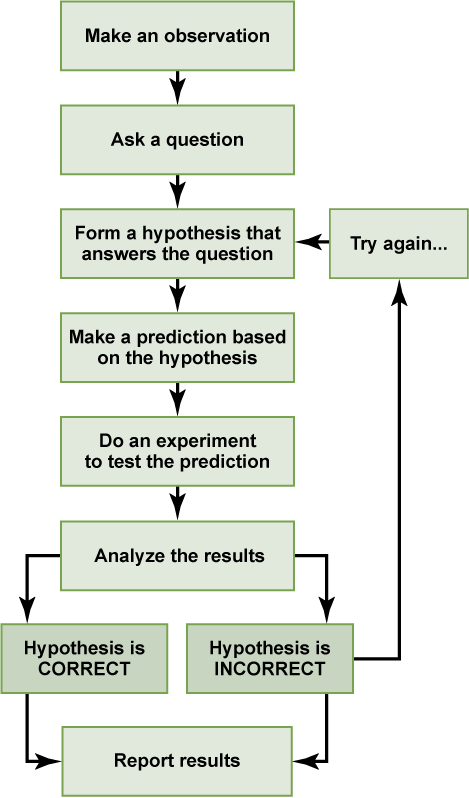
Finally, use observability tools to identify symptoms and narrow down the cause. The goal is disciplined, measured actions, avoiding the rush to “push many different buttons” for a quick fix.
RCA Followup
RCA stands for root cause analysis, this is the executive summary meeting for what the root cause was. Here is a format, and a supporting document to back up the format.
Meeting Format
- Introduction (5-10 minutes)
Welcome and introductions Purpose and objective of the meeting Ground rules
- Background and Problem Description (10-15 minutes)
Brief description of the complex system Details of the failure Impact on organization, customers, etc.
- Initial Analysis (15-20 minutes)
Timeline of events leading to failure Initial findings and observations Overview of data and evidence collected
- Root Cause Analysis (30-60 minutes)
Identification of potential root causes (use techniques like Fishbone Diagram, 5 Whys, etc.) Discussion and deep dive into potential root causes Validation of root causes
- Action Planning (15-30 minutes)
Proposed solutions or corrective actions Timeline for implementation Assignment of responsibilities
- Conclusion and Follow-Up (5-10 minutes)
Summary of key findings and decisions Schedule follow-up meetings or status updates Closing remarks
Document Format
A comprehensive document should be prepared to capture all the details from the RCA meeting. Here’s a recommended format:
Title Page
Title: Root Cause Analysis for [Failure/System] Date Author/Team Confidentiality Note if required
Executive Summary
Brief overview of the issue and key findings
Table of Contents
- Introduction
Background of the complex system Objectives of the RCA
- Scope
What is in Scope and not in scope, to support what the problem was
- Problem Description
Detailed description of the failure Impact and significance Supporting evidence and data
- Methodology
RCA approach and methods used (e.g., Fishbone Diagram, 5 Whys, etc.) Teams and stakeholders involved
- Analysis
Detailed analysis of potential root causes Validation and justification of identified root causes
- Recommendations
Corrective actions Preventive measures Timeline and responsibilities
- Conclusion
Summary and final thoughts
Appendices
Supporting documents, diagrams, charts, etc.
Acknowledgments
Revision History
This format ensures that the RCA is thoroughly analyzed and documented, providing a clear and actionable path forward to address the failure.
Resources
https://en.wikipedia.org/wiki/Five_whys
https://www.kitchensoap.com/2012/02/10/each-necessary-but-only-jointly-sufficient/
https://courses.lumenlearning.com/boundless-psychology/chapter/the-scientific-method/