Review of Flickr Architecture
Before we delve into the Postmortem let’s review the details of the database architecture and Flickr’s overall Architecture at that time. Flickr at that time was a PHP shop, running PHP 4, using Smarty as its template Engine in Apache running MODPHP. PHP was everyplace because it’s a great engine. I am sure that many hate this statement, that PHP is X or PHP is Y but in reality, it enabled Flickr to jump from a top 100 destination in the USA to a top 5 destination in less than 2 years. During these crucial 2 years, I was the main database architect and wrote a bunch of the PHP code that enabled Flickr to reach this level.
The next two images from @iamcal show the overall architecture of Flickr at that time
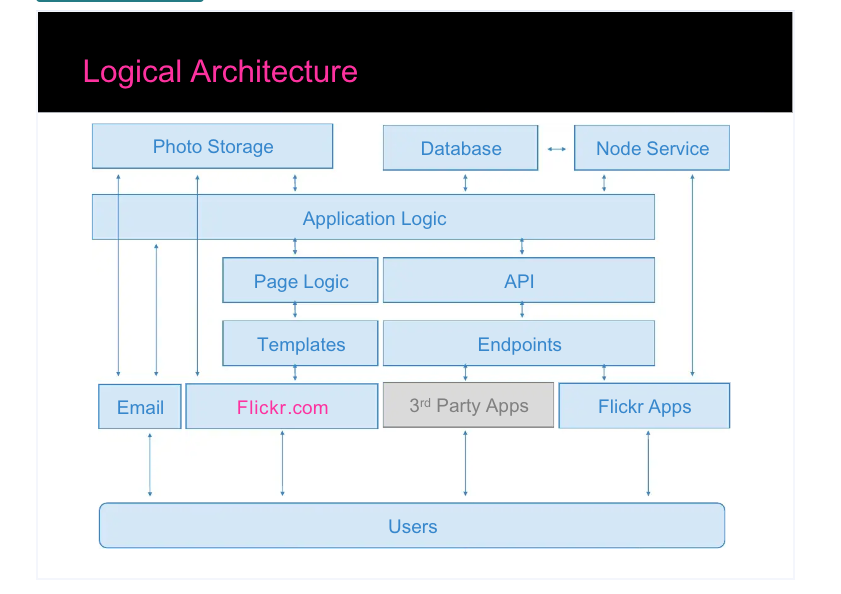
During my time the node service was not that big of a thing
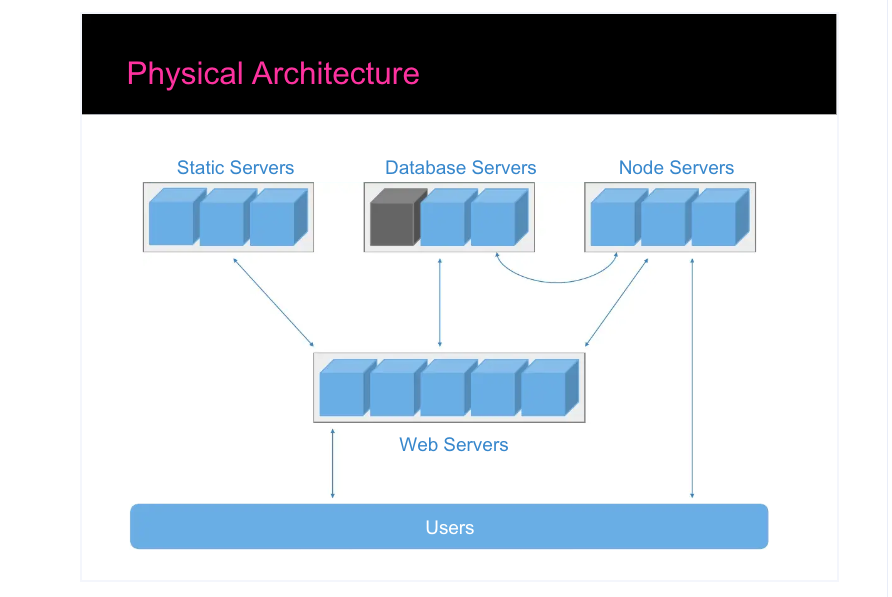
What is missing from this image is the cache layer for application data, it is combined with the DB layer just to be clear.
Now, let’s focus on what made the dynamic data respond so quickly for Flickr while handling all the load for millions of Daily Active Users, and typically being a destination for many viral-content endpoints from other social applications. One of the biggest events was in 2008 when Barak Obama won the USA Presidency, and all of his campaign photos including victory night were on Flickr. The Backend Held, the databases held, and Flickr served the content. I was exceptionally proud of Flickr during this time and the work I did for them. It was a great experience working for that Team.
History
The database design, setup, offline tasks, Memcache, the PHP code to render the activity feed, Sets, and Collections, along with Stats was my domain. Before we got to the level of handling all that traffic that Flickr was known for, the architecture was a single Main Database (huge) and a few followers that had constant follower lag. Note back in my day, we use to call this Master and Slave Topology but that is wrong for today, so I will focus on the terms of today.
I have been thinking since 1999 about how one solves a high write throughput while servicing huge amounts of reads. The Main server that handles the writes, with a bunch of read-only followers was a common Web approach of the time. It is perfect for when 90% of the traffic was read-only. Very easy to scale, but this was not Flickr. The ratio for Flickr was more than 40% writes and 60% reads.
The writes came from Photo uploads, tagging, 3rd party API access, and every single Photo View produced an update to the database photo view count realtime to show how many times that photo was viewed, and if the stream was also looked at a write realtime to show how many times that Photo Stream was viewed. Additionally, each Photo had a bunch of Machiene tags, and or tags so that we could search for photos. On top of that, each photo also has comments associated with it. Lots of writing activities.
How did we handle this?
Design to Attain the Goal to handle all the requirements of the product
ProblemWrite intensiveSolutionMore than one written sourceProblemMore than one written source, means multiple single points of FailureSolutionMake the write source redundantProblemWe want to make frequent changes to the schema, upgrade, and or allocate servers without a downtimeSolutionStick users (anonymous and logged in) to a server AND that single server needs to handle all the reads and writes if its pair went downProblemEverything has to be fast, if a page is slow, Flickr’s customers will be unhappy.SolutionSize the databases, to keep most of the data hot so queries that are all indexed can return data quicklyProblemReplication Lag, gives a bad experience, yet lag will happen becauseSolutionLet’s tie users to a server for both reads and writes in this design and eliminate the need to see replication. The only time a user could be exposed to replication lag is if the user’s server for the operation is down.
We will go into detail about each of the decisions and trade-offs in another section
The environment of the time
We have a general approach, to the design. Spread data out, we will detail how that is spread out at a later time, but to meet some of our solutions we need to have a server profile that will handle the load.
The great side effect of this approach is any server that can run MySQL, regardless of memory or IOPS throughput, can be used. For simplicity’s sake, and to set ourselves up with success, we have a single homogenous server environment for these MySQL servers to make the problem easier to scale and plan when we need new servers.
The Hardware was
- 4u
- 2 power supplies connected to 2 different power towers per rack
- 16GB of RAM
- 4 CPU per server
- with 6 15K RPM RAID-10 drives
- hardware raid with a Battery Backed Cache, the controller was an LSI with 128MB of memory to save data on a power outage.
- and a 256K STRIPE.
RAID-10 (also known as RAID 1+0) is a type of RAID configuration that combines both RAID 1 (mirroring) and RAID 0 (striping) techniques. In a RAID-10 configuration, data is first mirrored across two sets of disks and then the resulting mirrored pairs are striped together.
For example, in a 6-disk RAID-10 array, the disks are divided into three mirrored pairs. Data is written to one of the mirrored pairs and then mirrored to the other disk in the same pair. Then the resulting pairs are striped together for improved performance. The stripe size of a RAID-10 array refers to the size of the data blocks that are striped across the disks. The stripe size can affect the performance of the array, as well as the amount of wasted space due to partial stripe writes.
This RAID setup is a very important concept because essentially our RAID-10 disk setup conceptually is how our Shard Design is implemented. 2 Servers in a Main-Main config, where writes happen to one server and is mirrored to the other.
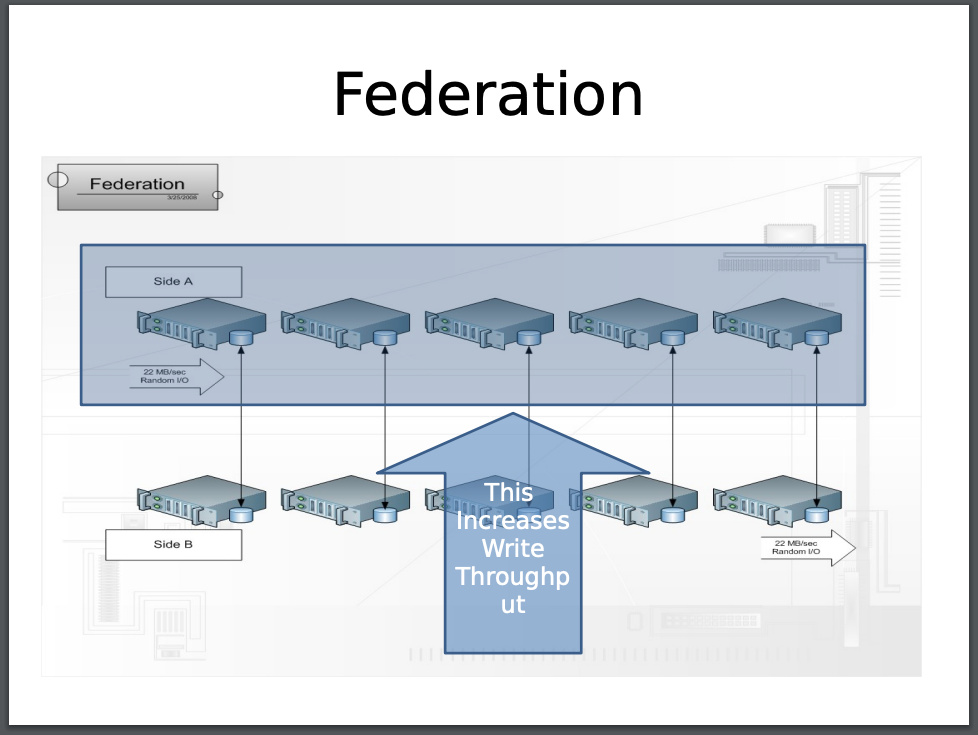
The MySQL setup at the time
mysql-4.1
Problem / Solutions Details
ProblemWrite intensiveSolutionMore than one written source
Imagine a database system where we are conceptually making a RAID-10 array out of database servers, but the database conceptually has all the data for a table on a single server originally. In a raid-10 system, there is no guarantee that all data for say the user’s table will be on a single server pair.

In the image above we can see that user 1 is allocated to a single shard-pair denoted as 1 server, the same with user 2, user 3, and user 4. This means that if I want their data, I need to query their server. So how do I know where their server is for Flickr?
We have a concept known as the Global Ring. The only thing that goes here, are Big-O(1) queries to tell the application where a user is located. Note in later designs I take ranges and store that in configs for the application to remove a lookup to Memcache and or the server itself - but this is how we did it at Flickr.
In this GLOBAL RING (the original Main server where data was moved out of) we supported the Lookup of OWNERID -> SHARDID PHOTOID -> OWNERID GROUPID -> SHARDID
ProblemWe want to make frequent changes to the schema, upgrade, and or allocate servers without a downtimeSolutionStick users (anonymous and logged in) to a server AND that single server needs to handle all the reads and writes if its pair went downProblemWe want to make frequent changes to the schema, upgrade, and or allocate servers without a downtimeSolutionStick users (anonymous and logged in) to a server AND that single server needs to handle all the reads and writes if its pair went down
We did all of the database shard logic in PHP, the PHP code of the time was rather awesome and clean, I learned a lot about what it takes to be a software engineer at Flickr.
When going to Flickr the user is cookied and a time is stored in that cookie, for anonymous users. That time was essentially the user_id. This is important because to get around Replication Lag, we needed a consistent experience for both logged-out and logged-in users. They always needed to hit the same server side when viewing other people’s photos (or their photos if logged in) or photo streams. We introduced a concept of a bucket. The bucket code was user_id % 2 and that was the side A or B that you would always hit unless that server on the side was down. This small concept also enabled us to bring down a side and perform maintenance like database alters, because back then we did not have online DDLs. This also means that a single server MUST be sized correctly to handle the load for that population of users if a server in a shard went down. This is also why we did not use a replication ring because if we had 3 servers, they can only handle 33% of the load, and require manual intervention to fix replication.
Finally, both servers needed to go down for users to experience an outage.
This bucket concept also fixes Replication Lag. Replication of the time only had 1 IO thread and 1 SQL thread, meaning 1 thread downloads the binlog, and 1 thread applies the changes. If the server starts lagging too much, this was a leading indicator to rebalance the server.
ProblemEverything has to be fast, if a page is slow, Flickr’s customers will be unhappy.SolutionSize the databases, to keep most of the data hot so queries that are all indexed can return data quickly
Roughly 400K users were stored on each Shard. If we had an influencer we would size that shard smaller, to a point where only 1 user could be on that shard. Flickr did not have an activity feed of your friends at the time, so we didn’t need to create activity feeds where there was a concept of popular users and the rest, such that forcing the architecture to write a user’s activity to their friends feeds, and popular users wrote their activity to every shard for feed generation.
Finally, we added a cache layer using Memcache to cache individual photo records and the 1st couple of pages of the photo stream. We would not hit the cache if the owner of the photo was looking at their photos, because we wanted to show the real-time number of views for that photo.
2005 Flickr outage affecting 1/16 of the user population of Flickr directly and everyone else indirectly
Name(s): Dathan Vance Pattishall
Date: Happened in 2005, modernized for 04/26/2023
Last modified: 04/26/2023
Summary
In Late 2005 or early 2006, the front ends were blocked on the backend, threads maxed out and our web servers became unresponsive causing a user-visible outage. The static farm was unaffected, and if photos were linked on other websites, the loaded find. Both 3rd party apps, and the Flickr apps, are also affected seeing an outage.
Normally in the summary, I would put the mitigation but I am going to wait until the end.
Impact
- 1/16 of the population was not able to load their streams or upload photos
- Apache threads built up not servicing requests
- Uploads did not process for some users
- an entire shard was offline due to blocked queries
- 3rd party applications went offline
Timeline
- 6 am 2005 - Pager goes off, offline queue is growing
- 6:05 am 2005 - An engineer responds to the page and indicates that Apache threads are maxed out
- 6:15 am 2005 - Shard-3a is holding 10000 threads open, all blocked
- 6:15 am 2005 - An engineer restarts all Apache servers
- 6:17 am 2005 - An engineer kills all queries on Shard-3a
- 6:30 am 2005 - An engineer removes Shard-3a from the pool
- 6:45 am 2005 - Alerts go off as Shard-3b is slowing down requiring selects to be killed
- 7:00 am 2005 - Apache threads are higher than normal, the system is back online for all users.
- 9:00 am 2005 - Shard-3a tests all pass and the server is put back in
- 10:30 am 2005 - Shard-3a exhibits the same behavior, the site is suggested, but some uploads fail
- 10:30 am 2005 - Shard-3a is also lagging from Shard-3b events
- 10:35 am 2005 - Shard-3a is removed from the config, Shard-3b becomes overwhelmed
- 10:40 am 2005 - An engineer locks all of shard-3 users and marks them for migration taking 1/16 of the population offline
- 10:45 am 2005 - An engineer starts the migration process of shard-3 users to the rest of the pool
- 9 pm 2005 - The migration finishes enabling all users to use the site
Root Cause(s)
Why did the Apache thread pile up?
- PHP makes an open query close connection on every page load. The MySQL server blocked, and had a setting of 10000 connections, that held open a large percentage of Apache threads
Why did MySQL lock?
- InnoDB indicates that threads were blocked on the Disk
Why did the Disk block the threads?
- An engineer noticed that the CPU block queue skyrockets periodically on the server and IOPS went to 0 for about 30 seconds
Why did all the CPU’s block queue skyrocket periodically?
- An engineer verified my.cnf settings
- An engineer verified O_DIRECT settings
- An engineer verified disk scheduler settings of DEADLINE
- An engineer verified nice settings
- An engineer used an LSI tool to look at the state of the Array all is ok and the health of the controller is marked fine
Why did the raid array report that the array is healthy if INNODB is blocking the disk subsystem?
- An engineer searched for the LSI firmware version and looked in a different section of LSI, and found that the battery is not responding
- An engineer looked at the change log for that firmware and found that the LSI controller will block all IOPS to protect the data saved if the battery does not respond to the probe
- An engineer realizes that this server has been in production without incident for 2 years nearly, and the battery is no longer healthy
The root causes are a few things:
- The database connection limit is too high for the number of Apache threads to service traffic.
- The battery probe times out in 30 seconds taking the array offline for that period for this special case and firmware version of the LSI controller.
- There was no visibility into the health of the controller from our monitoring system
Action Items
- monitor the controller and the raid array
- reduce the number of max connections
- replace all old servers batteries
- flash the firmware to not block but warn about battery failures.